An abstract workflow for BGP implementations
The first step to allow BGP implementations to be programmed is to have a clear understanding of how the BGP protocol operates and how it processes and sends messages. If we ignore the establishment of BGP sessions and the detection of failures, all BGP implementations need to implement the workflow described in the figure below.
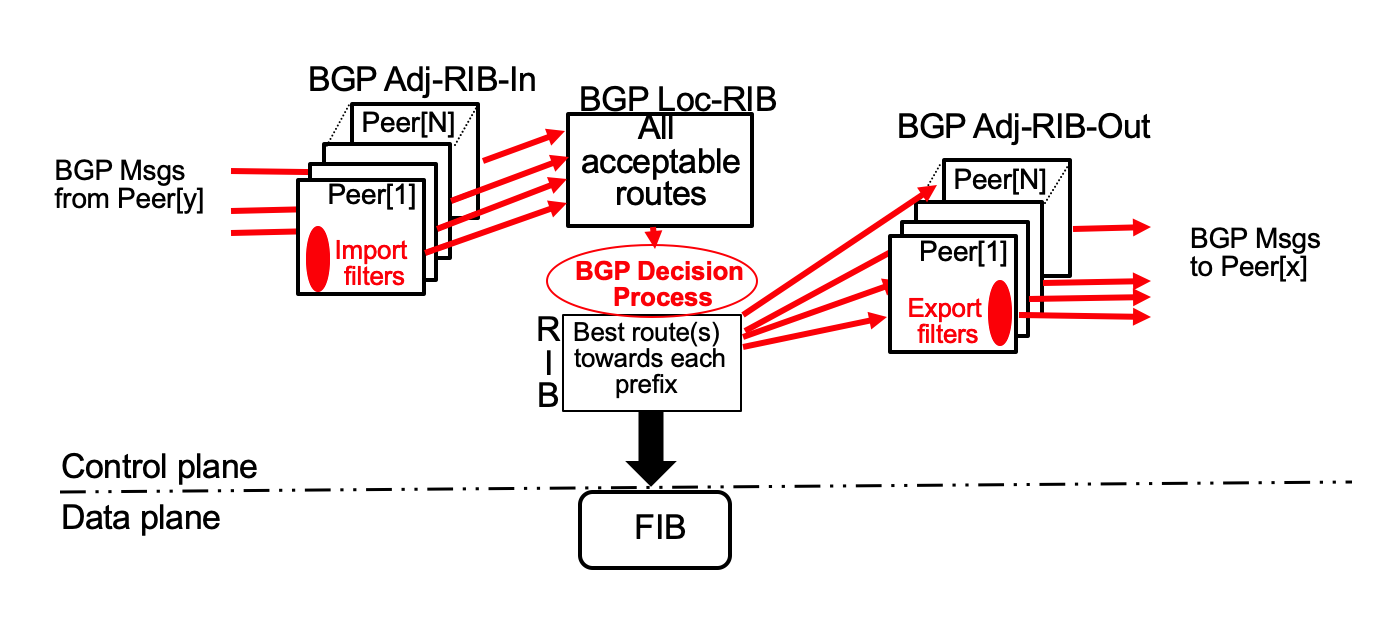
This workflow corresponds to the abstraction description of the BGP protocol in RFC4271. It illustrates the different datastructures that a BGP implementation must maintain and how BGP messages are processed. BGP messages are received on the left part of the figure and sent on the right. A BGP router maintains one BGP session with each peer. It stores several configuration parameters for each peer (IP address, AS Number, …) and associates an import filter to each peer. These filters are typically configured using vendor-specific commands or using NETCONF. When a BGP message is received over a BGP session it first passes through the import filter that may add or modify some of its attributes (e.g. local-pref or communities). It may also decide to discard the message (e.g. because it contains an invalid prefix). If the BGP message is accepted by the import filter, it is stored in the session’s BGP-Adj-RIB-In and then sent to the BGP-Loc-RIB. This RIB contains all the routes received from the different peers and accepted by their associated import filters. It is used by the BGP decision process to select the best route towards each IP prefix. This decision process is executed when a route is added or removed from the BGP-Loc-RIB and when the routes towards BGP nexthops change. The routes chosen by the BGP decision process are then pushed to the router’s FIB and advertised to peers, subject to the per-session export filters.
Starting from this workflow, one can identify five critical points in the processing of BGP messages. These points are identified with green circles in the figure below.
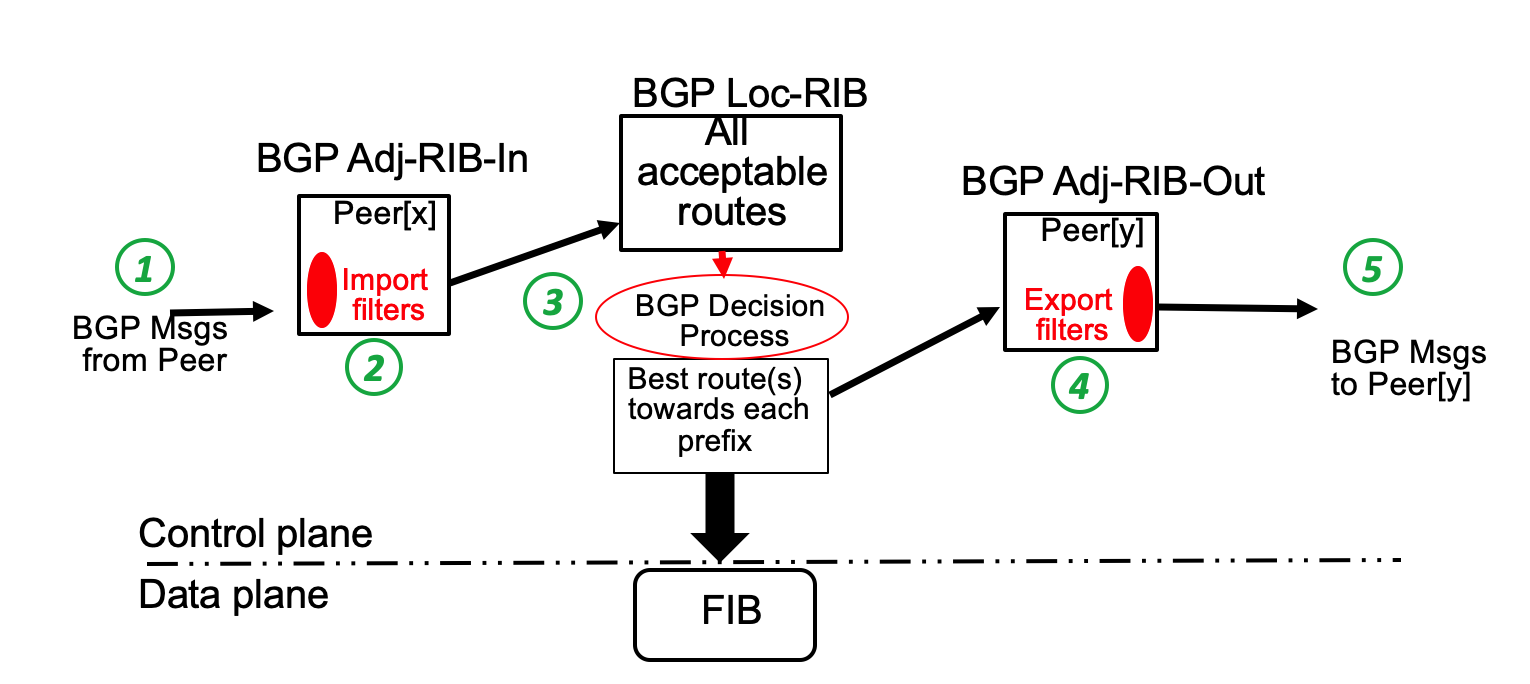
The first of these points is the reception of a BGP message from a peer. Several BGP extensions have defined new BGP attributes. This point is the part of the BGP implementation that parses the BGP message. To support a new BGP attribute, this is where a plugin could add new code to parse and process a new BGP attribute.
The second point corresponds to the import filters. This is a important part of a BGP implementation. When a new BGP attribute is defined, it typically needs to be supported in the import filter that could for example add the attribute to a BGP message or use its content in the filter.
The third point is the BGP decision process. This is a key part of a BGP implementation since network operators often need to tune the BGP decision process and modify how the best route is selected. By inserting plugins at this point, network operators
The fourth point corresponds to the export filters. As for the import filters, this is where new BGP attributes would be processed by the filters.
The last point is the encoding of the BGP messages that are sent to peers. This is where a new BGP attribute would be written before being sent on the wire.
In following blog posts, we’ll describe how plugins can be attached to these insertion points to support different types of BGP extensions.